
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 코틀린인액션
- 13460 구슬탈출 2
- 코틀린
- 싱글톤 컨테이너
- Kotlin in action 3장
- 고급매핑
- kotlin in action 정리
- Python
- 스프링 핵심 원리
- 20055
- 20055 컨베이어 벨트 위의 로봇
- 스프링 컨테이너와 스프링 빈
- 자바 ORM 표준 JPA 프로그래밍 7장
- 백준 13460 Python
- 백준 20055 컨베이어 벨트 위의 로봇
- 스프링 핵심 원리 이해
- 객체 지향 설계와 스프링
- 코틸린인액션
- 백준
- Kotlin in action 5장
- KotlinInAction
- Kotlin in action 10장
- 7장 고급매핑
- 컨베이어 벨트 위의 로봇 Python
- Kotlin
- spring
- 기능개발 python
- Kotlin In Action
- 스프링 핵심 원리 - 기본편
- Kotlin in action 6장
Archives
- Today
- Total
기록하는 습관
Elasticsearch (5) - 클러스터,Shard,Index 개념 본문
기본 용어

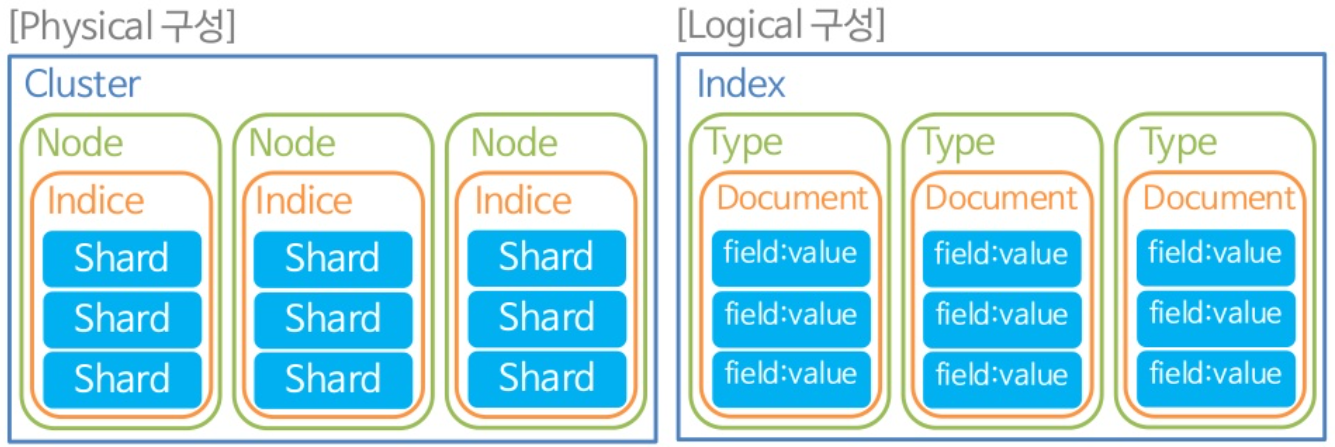
- 클러스터(Cluster)
- 물리적인 node 인스턴스들의 모임
- 모든 node의 검색과 색인 작업을 관장하는 logical 개념
- Index의 Document를 조회 할 때:
- master node를 통해 n개의 node를 모두 조회해서 각 data를 취합 후 결과를 하나로 합쳐서 반환함.
- 가용성, 확장성 측면에서 유연함
- 이유: cluster에 있는 node는 실시간 추가/제거가 가능하기 때문
- 인덱스(Index)
- 독립적인 데이터 저장 공간
- 하나의 index는 하나의 type만 가짐.
- 하나의 물리적인 노드에 여러 개의 논리적인 index 생성 가능.
- 만약 ES를 분산 환경으로 구성하면, 하나의 index가 여러 node에 분산되어 저장됨.
- Index 이름은 모두 소문자여야 함.
- Index가 없는 상태에서 데이터가 추가되면 index가 자동 생성됨.
- shard(Shard)
- 색인된 문서는 하나의 index에 담김.
- 색인된 데이터는 물리적인 공간에 여러 개의 파티션으로 나뉘어 구성되는데, 이 파티션을 shard라고 함.
- 인덱스가 생성된 후에는 shard 개수 변경이 불가능.
- 종류
- Primary Shard
- 각 index 별로 최소 1개 이상 존재해야 함.
- Index에 n개의 document를 색인하게 되면 설정된 shard 수 만큼 분산 저장됨
- Replica Shard
- Primary shard의 복제본
- Replica shard의 개수 == primary shard를 제외한 복제본 수
- Primary Shard
- 다수의 Shard로 document를 분산 저장하고 있어 데이터 손실 위험을 최소화 할 수 있음.
- 장애가 발생하면 master node는 데이터를 재분배 하거나, replica shard를 primary shard로 승격시켜 서비스 중단 없는 복구 가능.
- 위 상황에서 Node1에 장애가 발생해도 나머지 노드에 모든 replica shard가 존재하므로 중단없이 복구 가능.
- N개 node에서 장애가 발생했을 때
- 최소 n+1개의 node가 동일 cluster 내에 존재해야 함.
- Replica의 수는 최소 n개 여야 함.
- Replica 개수 == 전체 node 수 - 1
- 만약, cluster의 node에 문제가 발생해 가용한 node 수 <= replica의 수
- 어떠한 노드에도 할당되지 못한 shard가 발생하게 됨
- 이런 경우 cluster status “YELLOW”가 된다.
- 만약, cluster의 node에 문제가 발생해 가용한 node 수 <= replica의 수
- 장애가 발생하면 master node는 데이터를 재분배 하거나, replica shard를 primary shard로 승격시켜 서비스 중단 없는 복구 가능.
- 타입(Type)
- Index의 논리적인 구조
- 7.0 이후 버전부터 지원 중단
- 문서(Document)
- 데이터가 저장되는 최소 단위
- 기본적으로 JSON 포맷으로 저장됨.
- 하나의 Document는 다수의 field로 구성.
- 문서 안에서 문서를 저장하는 중첩 구조도 가능함.
- 필드(Field)
- 문서를 구성하기 위한 속성
- Column과 비교할 수 있으나, 좀 더 dynamic한 데이터 타입.
- 하나의 field는 목적에 따라 다수의 데이터 type을 가질 수 있음.
- 매핑(Mapping)
- 문서의 field, field의 속성을 정의하고 색인 방법을 정의하는 프로세스.
- Field명은 중복해서 사용할 수 없음.
* ES가 대용량 처리가 가능한 이유
- RDBMS: 모든 요청을 하나의 Server에서 처리
- ES: 다수의 Server로 분산해서 처리하는 것이 가능
-> 분산 처리를 위해서는 다양한 형태의 node들을 조합해 cluster를 구성해야 함.
'개발 > Elasticsearch' 카테고리의 다른 글
| Elasticsearch (7) - Elasticsearch와 Lucene (0) | 2022.07.06 |
|---|---|
| Elasticsearch (6) - 노드의 종류 (0) | 2022.07.06 |
| Elasticsearch (4) - 동의어 사전 (0) | 2022.03.12 |
| Elasticsearch (3) - reindex (0) | 2022.03.12 |
| Elasticsearch (2) - index 최적화 방법 (0) | 2022.03.12 |
'개발/Elasticsearch' Related Articles
more




Comments